Day 4 ) 캠프 넷째날, 실습
> Diary
오늘은 캠프시간에 다양한 data set 을 가지고 실습을 진행한다.
지금까지 돌려본 코드를 다시 보면서 익히는 시간을 아침시간에 가져보려고 한다.
오늘도 내 전공에 대한 정상적인 마음가짐을 가지고, 내 꿈을 향해 한걸음 내딛는 시간이 되었으면 좋겠다.
오늘 새벽 교회 지체 분이 돌아가셨다. 그리고 내일부터 공식적인 예배 외에 모임을 금지한다고 한다. 참 많은 생각이 들었다. 오늘 하루 꿈에만 가까워 지는 것이 아니라, 예수님께 더욱 가까워 지는 하루가 되었으면 좋겠다.
이 모든 것 전에, 주님이 아니면 아무것도 아니기 때문이다. 무엇을 위해 하루를 사는가는 굉장히 중요하다.
배움을 가질 수 있는 것에 감사하며 오늘 하루 감사함으로 최선을 다 했으면 좋겠다.
살면서 나의 도구를 가지고 세상에 있는 어떤 문제를 해결하고 싶다. 하지만 그 전에 주님이 없다면 그 어떤 의미가 있는가. 정상적이라면 당연히 할 수 있는 일 이전에 주를 먼저 바라보기 원한다.
느리던지 빠르던지 그 발걸음을 인도하시는 분은 주님이시다.
이번 방학이 정말 중요하니까, 다시 돌아오지 않는 시간이니까,
갖출 수 있는 도구는 다 갖춰야지
겸손하게!
오늘부터 수학
통계 부분 좀 보고 선대를 공부한다.
영어도 늦추지 말아야지
미니팀프로젝트가 주어졌다.
최고로 최선을 다하는 시간이 될 것이다.
넘치도록 부어주시는 분께 의뢰하며, 최선을 다 해야겠다.
감사하다.
> ML Study
sklearn package 안에 있는
--
GridSearchCV 는
각각의 파라미터로 모델을 여러개 만들어 최적의 파라미터를 찾아주고
교차검증도 가능하게 해준다.
예시 )
1. XGBoost.XGBClassifier()로 빈 모델을 만들고,
2. XGBoost의 원하는 파라미터를 dict형태로 만들어놓고,
3. KFold() 지정해주구요
4. GridSearchCV()안에 1-3번들을 다 넣어주어 모델을 만듭니다.
5. 만들어진 모델로 fit하고, 최적의 파라미터를 찾습니다.
--
list (zip(x[:5],y[:5])) 을 하면, 일정한 개수로 이루어진 자료형을 묶어주는 역할
자료형의 i-th 에 해당하는 요소(elements)를 묶어주는 함수
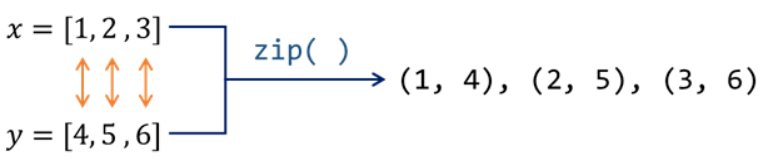
출저 : 점프투파이썬
--
용어정리
https://m.blog.naver.com/qbxlvnf11/221449297033
머신 러닝 - epoch, batch size, iteration의 의미
- 출처이번 포스팅의 주제는 텐서플로우나 케라스 등을 사용해서 모델을 만들어 보았으면 다들 아실 용어인...
blog.naver.com
-한 번의 epoch은 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
epochs = 40이라면 전체 데이터를 40번 사용해서 학습을 거치는 것
epoch 값이 너무 작다면 underfitting이 너무 크다면 overfitting이 발생할 확률이 높은 것 -> 적절 값 설정 필요
-batch 는 나눠진 data set 을 의미
-iteration
메모리의 한계와 속도 저하 때문에 대부분의 경우에는 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수는 없다. 그래서 데이터를 나누어서 주게 되는데 이때 몇 번 나누어서 주는가를 iteration, 각 iteration마다 주는 데이터 사이즈를 batch size.

출처: https://www.slideshare.net/w0ong/ss-82372826
텐서플로우로 배우는 딥러닝
저희과 학생들을 위해 만든 입문 발표 자료입니다.
www.slideshare.net
-분산(variance)은 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다. 즉, 차이값의 제곱의 평균이다. 분산은 기준으로 부터 variability 를 보여주기 때문에 기준이 다른 값을 normalization 하는데에 사용.
--
split 할때 random_state 값 지정은 반복 연산 시에 동일한 결과를 얻어 볼 수 있게 한다.
iteration 연산 마다 값이 바뀌지 않게 한다.
정수 값을 입력하면 숫자를 random하게 생성할때 사용되는 seed 숫자로 사용되며,
None을 입력하면 np.random에서 제공하는 random number generator가 사용됨.
-> On a serious note, random_state simply sets a seed to the random generator, so that your train-test splits are always deterministic. If you don't set a seed, it is different each time.
표준화 작업을 하면 gradient descent 의한 웨이트 업데이트 과정의 학습 효율이 증가
참고자료 : https://steemit.com/kr/@codingart/1-5-iris-flowers-data-sklearn
1-5 Iris flowers data 머신 러닝을 위한 sklearn 라이브러리 활용 — Steemit
머신러닝 라이브러리에 텐서플로우만 있느 것이 아니다. 또 하나의 강력한 툴로 알려진 scikit-learn 라이브러리를 사용하여 머신러닝을 해보자. sklearn에서 Iris flower data set을… by codingart
steemit.com
--
> parameters
n_estimators 는 생성할 tree 의 수를 나타낸다. citerion 는 분기를 결정하는 방법
GridSearchCV cv -> k-fold 의 k 를 정해주는 것. ( 몇개로 쪼갤건지 )
근데, code 에서 test 랑 train 이랑 split 해줬는데 , cv 를 ( test 와 train 을 나눠서 iteration 하며 검증하는 cross validation 을 위한 k 값 ) 왜 또 정의해 주는거지? 아래의 설명에서도 split 안할때 말하는거 아닌가?
K-Fold Cross Validation(교차검증) 정의 및 설명
정의 - K개의 fold를 만들어서 진행하는 교차검증 사용 이유 - 총 데이터 갯수가 적은 데이터 셋에 대하여 정확도를 향상시킬수 있음 - 이는 기존에 Training / Validation / Test 세 개의 집단으로 분류하�
nonmeyet.tistory.com
--
dictionary unpaking 하면 element 나옴.
캠프내용
오늘 실습을 한다고 적혀있었는데, 실습보다는 Neural Network 에 대해서 강의를 들었다.
여기 저기 , 부분 부분 헛갈리고 정확하게 개념이 잡히지 않은 부분이 있는데
이런 부분을 차근 차근 책을 하나 해서, 읽어 가며 정리 해야 겠다. 물론 코드 다루는 거랑 같이
시간이 없다 하면 없는거고, 해야 할 일에 대한 시간을 만들어야 한다.
이번 방학은 중요하고, 또 꿈이 있기 때문에.
영어, 수학, coding, DS, algorithm, 이번에 배운 주요 과목 (OS) , 인턴이랑 교환 알아보기
Perceptron 은 linear 한 모델이기 때문에,
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
인공신경망 ( perceptron)은 수많은 머신러닝 기법 중의 하나이다.
그런데 이러한 퍼셉트론을 여러겹으로 쌓아올린 기능이 기존의 머신러닝 방법보다 훨씬 좋게 나옴
이것을 ( Neural Network ) 라고 한다.
Neural Network 가 무엇인지 이해하기 전에, 먼저 perceptron 이 무엇인지 이해해야 한다.
> perceptron

여러개의 입력값으로부터 하나의 출력값을 내어놓는 것이다.
입력 값마다 weight 가 있고, rm summation 을 구한다
summaiton 이 임계값 ( theta ) 보다 큰 값을 가지면 이는 -> 1 로 출력이 되며
임계값 보다 작은 값을 가지면 -> 0 으로 출력이 된다.
ddl theta 를 summation 부분으로 넘기면 이 부분이 바로 bias 가 된다.
이런 bias 처럼, 뉴런에서 출력값을 변경시키는 함수를 활성화 함수(Activation Function)라고 합니다
이 activaiton function 에는 여러가지가 있는데,
-> 초기 perceptron 에서는 이 activation function 으로 step function 을 사용함 ( -> 0 과 -> 1 로 출력된것을 알 수 있다시피 )

-> 활성화 함수를 시그모이드 함수로 변경하면 방금 배운 퍼셉트론은 곧 이진 분류를 수행하는 로지스틱 회귀와 동일함을 알 수 있습니다.

다시 말하면 로지스틱 회귀 모델이 인공 신경망에서는 하나의 인공 뉴런으로 볼 수 있습니다. 로지스틱 회귀를 수행하는 인공 뉴런과 위에서 배운 퍼셉트론의 차이는 오직 활성화 함수의 차이입니다.
시그모이드 함수에 대한 설명 : https://icim.nims.re.kr/post/easyMath/64
활성함수(Activation) 시그모이드(Sigmoid)함수 정의 | 알기 쉬운 산업수학 | 산
icim.nims.re.kr
아주 좋은 자료:
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net