Day 2 ) 캠프 둘째날, Decision tree 와 Visualization
Diary ( 7.7.20 )
오늘은 겸손한 자세를 유지 하는 것이 중요하다는 것을 알았다. 배우는데에 있어서 두려움은 겸손하지 않음에서 오는 것 같다.
그리고 꿈이 있다면 걱정 하지 않고 ( 고민은 필요하다 ) 바로 하는 것!
어떤 것을 배우고 학습한다는 것에는 어려움이 따른다는 것. 익숙해 지는 것. 발전하고 나아간다는 것. 도구가 된단것.
그렇게 오늘 하루도 감사하며 배우자. 언젠가는 흘려 보낼 그날을 기대하며. 내 전공은 정말 멋진거 같다.
내가 모든 새로운 것을 받아들일때 외우고자 하는 강박이 있다는 것을 알았다. 그것을 좀 내려놓아야 겠다.
직접 하는 시간 미루지 말고 현장에서 집중하기! 그리고 다른 사람과 특히 신경쓰거나 비교하는 마음set 버리기.
지극히 정상적인 사람은, 내 직업을 잘 하는 사람이다.
-----------------------------------------------------------------------------------------------------------------------------------
흐아 캠프 끝나고 왔는데 너무 힘들다 오늘은 핏자를 먹어줘야 겠다. 긱사 같이 사는 언니랑 동생이랑 저녁약속을 잡았다. 오늘은 학교가 더 예뻤다 햇빛에 반사된 에쁜 초록색이 가득한 우리학교가 넘 좋다. 감사하다.
ML Study ( 오늘 배울 내용 빠르게 예습 부분 )
> 예습 2 일차 노트에 오늘 배울 decision tree에 대해 정리 했고,
어제 강의 시간에 , data 를 시각화 하는 단계에 대해서 잠깐 언급 해 주셨다.
data 시각화가 왜 필요할까?
> 어제 세션 1 시간에 다룬 내용
AI > 머신러닝 (통계) > 딥러닝 ( 뉴럴 네트워크 )
AI 는 사람의 행동을 기계에 구현하려는 시도
머신러닝을 하려고 할 때 어떻게 해야 하나
data 필요 -> 데이터를 사용할 모델 ( 데이터의 패턴을
캡쳐 한 것이 모델 ) 을 만드는 이 과정을 트레이닝이라고 한다.
aabc aabc 이런 패턴으로 데이터 구성되어 있으면
data가 이런식으로 들어있다고 트레이닝 시킴
-> 새로운 데이터를 모델에 넣으면 abcc 이런 것을 또 캡쳐 할 수 있게
만듬
abcc 가 인식이 안되면 오버피팅 되었다고 해서
두개 다 예측할 수 있는 모델을 만들 수 있는게
우리의 목표
ETL 과정 ( Extract, Transform, Load )
1) 데이터를 준비
2) 데이터를 수집 ( 수집 한 것 중에
없는 데이터 , 쓰레기값이 있는 데이터 있으니까
preprocessing 에서 비어있는 칼럼, 평균이나 standard 값으로 채워 넣거나
없애는 과정을 거침
3) 의미없는 결과 값들을 제외 하고 , 나머지에서 뽑아내서 분석
각각 분석하는 기준이 나이, 키 , 학점 있다 하면
학교생활을 분석하는데 키는 중요하징 낳으니 컬럼을 버리고 train 시켜야 정확한 분석이 나오니까
이런 과정이 analysis.
4) 걷어낸 데이터를 적용해서 모델을 만들어냄
5) visualization 을 해서 data 가 어떻게 구성되어 있는지 확인
어떤 data 에 weight 를 주면 되겠다. 이런 식으로 생각
6) 트레인을 시킨 다음에 아무나 사용 할 수 있는 모델을 만들어냄
금요일날 데이터 셋을 가지고 머신러닝을 돌려볼것임
( 공프기 팀끼리 모여서 , 어떻게 내 데이터에 적용할지 생각하면서 배우기 )
각 모델마다, 모델의 장단점이 있다. 예를 들어서
yes or no -> decision tree 가 좋을 수 있음.
KNN 오늘 , 내일 decision tree, regression 배우고.... 마지막으로 deep learning 배울거에요 !
바로 이 5) 번 부분이 data visualization 이 필요한 부분이다.
정리된 data 를 가지고 모델을 만들어 냈을 때, 데이터가 어떻게 구성되어 있는지 확인 하고
어떤 data에 weight 을 줄건지 확인하기 위해 거쳐야 하는 과정인 것.
그렇다면, python 에서 데이터를 시각화 하는 다양한 방법 중,
참조 : https://zzsza.github.io/development/2018/08/24/data-visualization-in-python/
Python에서 데이터 시각화하는 다양한 방법
Python에서 데이터 시각화할 때 사용하는 다양한 라이브러리를 정리한 글입니다 데이터 분석가들은 주로 Python(또는 R, SQL)을 가지고 데이터 분석을 합니다 R에는 ggplot이란 시각화에 좋은 라이브러
zzsza.github.io
내가 사용할 방식은 Matplotlib 라이브러리를 이용한 방식이다. 이는 python 에서 가장 많이 쓰는 라이브러리다.
설치 :
pip3 install matplotlib
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt print("Matplotlib version", matplotlib.__version__)
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
Matplotlib version 2.2.3
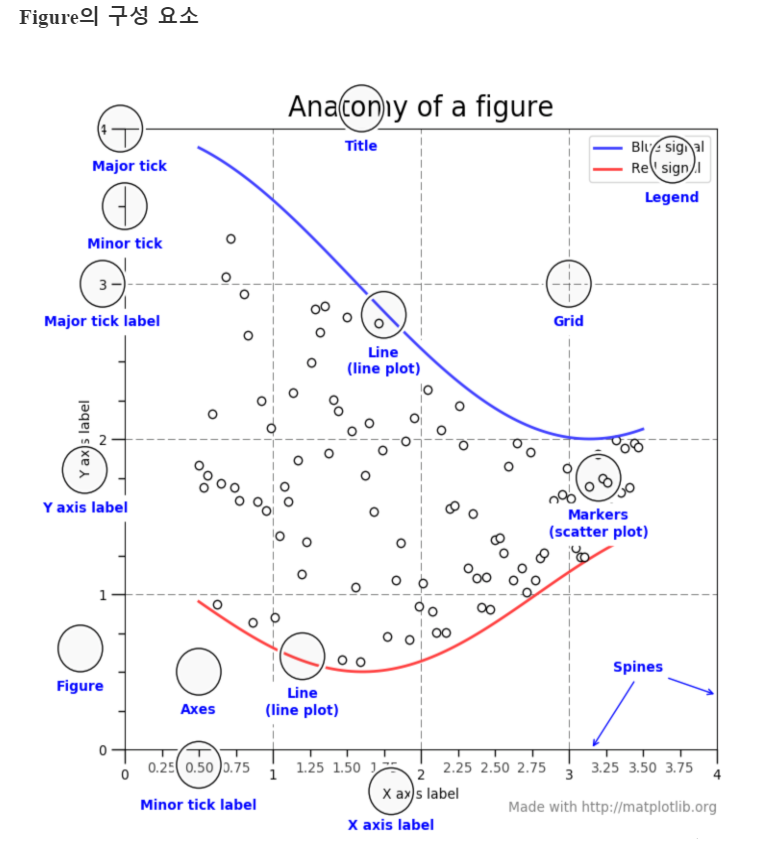
>그래프와 관련된 명칭
-figure 는 그림이 그려지는 도화지
-plt.subplots 도화지 분할해서 각 부분에 그래프 그리는 방식으로 진행.
-plt.figure를 명시적으로 표현해주는 것이 좋으나, plot 함수에서 자동으로 figure를 생성하기 때문에 자주 사용안함. figure에 접근해야 할 필요성이 있다면, plt.gcf() 로 접근.
-size 조절

> 여기서 부터는 오늘 들은 수업 정리
> 오늘의 session 1 python
저번시간 복습 !
KNN 은 거리로 하기 때문에 normalization 을 한다고 했고
k 를 정하는 것도 중요하다.
python 의 실체! session 을 먼저 들었다 ㅎㅎ
python 의 fact !
java 에 포인터 없는 것처럼 포인터 없고
C 는 리스트를 보내주는 방식으로 return( 여러개 할 수 있지만 )
pyhton 은 여러개의 return 을 가질 수 있음
a,_, _, b,c = func() 이렇게 선별적으로 return 값 받기 가능 !
for 문 안에 if else 있을 수있음. if 안에
break 가 걸리면 else 실행 안하고 끝나버림.
list 나 tuple 은 unpacking 을 할 수 있음 ( list 와 tuple 의 차이점은 tuple 은 mutable 하다는 것 )
colors =['red', 'green', 'blue', 'yello', 'cyan']
print(*colors)
# foo_list=(3,4)
# print(*foo_list)
bar_dict = {'y':3, 'z':4}
# print(**bar_dict)이렇게 하면 error
def point(y,z):
print(y,z)
point(**bar_dict)
# dictionary 같은 경우는 key 값 정확하게
enumerate 사용하면 index 랑 value 랑 같이 가져올 수 있다.
vowels = ['a','e','i','o','u']
for i, letter in enumerate(vowels):
print(i, letter)
Inf 값 적으면 infinite 값 들어감
-Inf

조건에 맞으면 boolean
append , extend 다름
append 를사용해서 list 를 build 할 수 있고,
예 ) a = []
for x in range (0,10):
a.append(x)
print(a)
#list comprehension 으로
for x in range (0,10):
print([x for x in a])
이렇게 쓸 수 있다.
list 에서의 slicing


> Session 2 Decision Tree (DT)
의사 결정 나무 모델도 supervised 학습 법으로 학습시킨다. ( KNN 과 마찬가지 )
data 를 질문을 해가면서 분류하는 모델
엔트로피를 크게 줄이는 질문을 먼저 하는 디시션 트리
interor node 질문에 해당하는 노드
leaf node 에 의해서 의사결정이 된다.
어떻게 예측 ? 그르고
트리는 어떻게 만드냐 ( depth 는 사용자가 입력해 준다. )
leaf node 에 해당하는 값으로 의사결정을 한다. -> 예측 결과
딕셔너리 중첩 -> 딕셔너리 아니면 leaf node 이다. ..?
질문을 어떻게 split 하느냐 , 데이터 기준을 어떻게 잡느냐
-> 이에 대한 기준이 되는 것이 엔트로피 이다.
복잡도( 어떤 식에 대한 값이 ) 에 대한 값이 엔트로피
엔트로피를 줄여주는 방향으로 split 을 결정 해야 하는데,

> Session 3 Random forest and Visulization data ( DT)
DT overfitting 이 문제이다.
예 ) 사과와 오렌지의 DT 와 RF 의 비교가 아주 좋았음
train data 에 대해서 계속 바뀔수 있음 -> 해결 : randong forest
투표를 통해 분류되는 결과에 대한 결정을 내림
DT 의 단점 : training data 에 대해서는 정확도가 올라가지만,
test 에 대해서는 떨어짐 ! -> 이를 오버 피팅 되었다고 하며 모델이 불안정하다고 한다.
이를 극복하기 위해 random forest 를 이용.
Random forest 는 앙상블 학습 중의 하나이다. : 여러개의 decision tree 사용 한개보다 더 좋은 결과
앙상블 학습은 여러개 있는데, 내일 더 자세히 !
random forest 로 얼굴 인식에 쓰이고 센서 인식 ( 닌텐도 )
이럴 때 정확도를 높이는데 많이 사용됨
이게 영상에 쓰이는 특별한 이유가 있나요?
data 를 질문을 해가면서 분류하는 모델
decision tree와 비교를 하자면
randon forest 는데이터의 중복을 허용, 각 decision tree 마다 data 의일부를 사용
엔트로피를 크게 줄이는 질문을 먼저 하는 디시션 트리 VS
렌덤 포레스트는 질문을 랜덤으로 고름 ( 굳이 좋은 질문을 구하지 않아도 됨 )
투표 : aggregate 와 같은 말
투표로 다반수 결정을 통해 결과로 더 많이 나온 apple 을 !! 선택 할 수 있다.
예시가 아주 맘에 들었음 ! 첨부할 예정..
여러개의 모델을 학습해서 그 결과로 더 좋은 결과 낼 수 있는게 Random forest 임
>session 4 visualization!
decision tree 시각화 ! -> metplotlib 데이터 시각화 패키지!